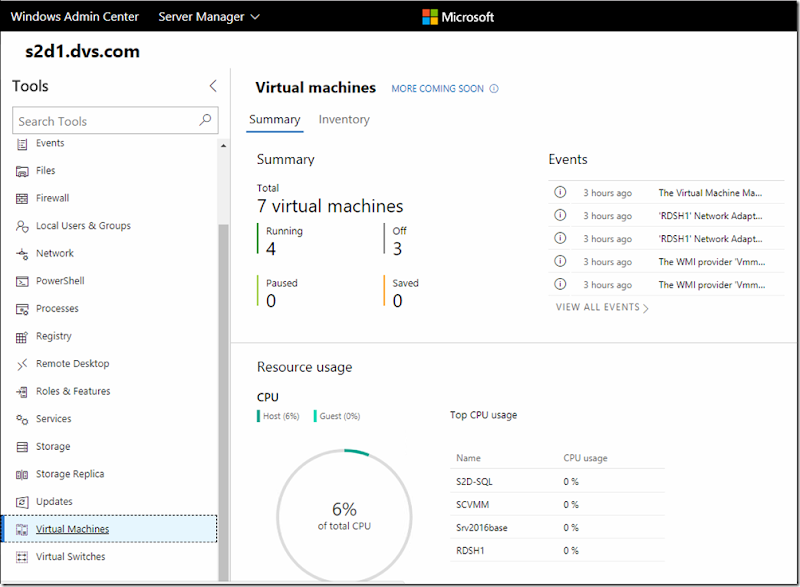
Credit: BitFenix
I can’t believe it’s time already, 2 years has flown by! I’ve managed to stick to a 2-year upgrade cadence for the last 8 years, performing meaningful upgrades at each interval. This year I debated skipping but I pressed forward as there are a few key technologies I want to enable: Pascal GPU, M.2 NVMe, DDR4 RAM and the Z270 chipset. 2 years is also a great time frame for reasonable cost reclamation on my used parts. The new Kaby Lake CPU upgrade doesn’t look to be a massive jump from the Haswell chip I ran for the past 2 years (4790K) and an even smaller step from Skylake. In case you want to check out my previous builds they can be found here and here.
I plan to reuse my BitFenix Phenom M Micro-ATX case which I absolutely love, my amazing Noctua NH-U12S CPU cooler + case fans and my Silverstone ST55F PSU, but those will be the only holdovers.

Motherboard
Micro-ATX is still the smallest form factor that works for me given what I want to achieve and I endeavor to go as small as possible. The Asus ROG Strix Z270i came very close to pushing me into Mini-ITX. For this build I need 2 x M.2 slots and like the idea of having a 2nd PCIe slot should I want to do SLI at some point. 2 x DIMM slots is doable to run the 32GB RAM I need but again, no expansion while reusing my existing investment. So I stayed with mATX and went with the Asus Prime Z270M-Plus which will suit my needs without a lot of extra pizazz. There are a number of considerations in the Asus mobo lineup as well as in the Intel chipsets. The graphic below highlights the key features of my new board. Most notably, RAM clock support up to 3866MHz, a USB Type-C connector in the IO panel, dual x4 M.2 slots positioned optimally below the PCIe slots, Intel Gb NICs and SafeSlot Core which provides PCIe slot strength to hold those heavy GPUs.

Credit: Asus
Asus put together a great blog post that details all their current motherboard product lines and how they are differentiated. In short the Prime line is the all-around mainstream offer without a ton of extravagances, TUF is the military spec with drop resistance, Strix is geared at the gaming crowd with 5 levels (low to high) and supports higher RAM clocks, ROG is aimed at people who consider themselves enthusiasts with extra lighting support, overclocking options and the highest available RAM clocks. Having bought ROG boards in the past and not used a fraction of the extra stuff they come with, I took a serious feature evaluation on exactly what I need in a motherboard. Prime suits my needs just fine and the saved $ is welcomed.
Chipset
The 270 is the new chipset for the 7th gen Intel proc and comes in “Z” or “H” variations. Z for consumers includes features like overclocking while H is geared more for corporate builds with less features. New in the 200 series chipset is support for Intel’s Optane NVMe and dual m.2 slots with dedicated PCIe lanes. Both Skylake and Kaby Lake CPUs use the same 1151 socket and are interchangeable on either 100 or 200 series boards. Below is a PCH feature comparison of the 4 most relevant configurations at the moment. You notice the biggest difference between the 170 and 270 are more IO/PCIe lanes. Also on the 170 chipset, a M.2 device cost 2 x SATA ports since these share PCIe lanes (same on the Z97 boards), this tax has been removed on the 270.
|
Chipset
|
Intel Z270
|
Intel H270
|
Intel Z170
|
Intel H170
|
|
SKU Focus Segment
|
Consumer
|
Consumer / Corporate
|
Consumer
|
Consumer / Corporate
|
|
CPU Support
|
Kaby Lake-S / Skylake-S
|
Kaby Lake-S / Skylake-S
|
Kaby Lake-S / Skylake-S
|
Kaby Lake-S / Skylake-S
|
|
CPI PCI-e Configuration
|
1 x 16 or 2 x 8 or 1 x 8 + 2 x 4
|
1 x 16
|
1 x 16 or 2 x 8 or 1 x 8 + 2 x 4
|
1 x 16
|
|
Independent DisplayPort
|
3
|
3
|
3
|
3
|
|
Memory DIMMs
|
4
|
4
|
4
|
4
|
|
Overclocking
|
Yes
|
No
|
Yes
|
No
|
|
Intel SmartSound Technology
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Intel Optane Technology
|
Yes
|
Yes
|
No
|
No
|
|
Intel Rapid Storage Technology
|
15
|
15
|
14
|
14
|
|
Intel Rapid Storage Technology From PCIe Storage Drive Support
|
Yes
|
Yes
|
Yes
|
Yes
|
|
RAID 0,1,5,10
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Intel Smart Response Technology
|
Yes
|
Yes
|
Yes
|
Yes
|
|
I/O Port Flexibility
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Maximum High Speed I/O Lanes
|
30
|
30
|
26
|
22
|
|
Total USB Ports (Max USB 3.0)
|
14 (10)
|
14 (8)
|
14 (10)
|
14 (8)
|
|
Max SATA 6 Gbps Ports
|
6
|
6
|
6
|
6
|
|
Max PCI-E 3.0 Lanes
|
24
|
20
|
20
|
16
|
|
Max Intel RST for PCIe Storage Ports (x2 M.2 or x4 M.2)
|
3
|
2
|
3
|
2
|
CPU
Intel is making it less difficult to choose a desktop CPU these days with far fewer overall options if you want a higher-end unlocked CPU under $500 and aren’t upgrading from a recent gen. If you want the best 8 core desktop CPU Intel has to offer and have no budget, look no further than the i7-6900K. If you’re upgrading from a 4th or earlier gen i7 the choice is simple: i7-7700K (14nm). If you have a Skylake CPU already (i7-6700K, also 14nm) there is no need to upgrade as any performance gain will be minimal. If you’re like me coming from Haswell (i7-4790K), the performance gain will be at best in the 10% range and may not be worth it, unless also like me, you want to upgrade to enable other specific features. It’s odd to put this in print, but for this build the CPU is actually the least exciting thing I’m adding here! It also appears that this trend will continue for the next few generations of Intel CPUs, so I might not be upgrading again in 2 years. Between the 6th and 7th generation CPUs mentioned above, the only improvements on the Kaby Lake are: +200MHz base clock (times 4 cores), +300MHz to Turbo, increased DDR4 speeds, and new embedded graphics gen, same socket, same 91W TDP. There just isn’t much here to warrant an upgrade from 6th to 7th gen sadly.

Another alternative if you’re tired of the stale and uninspiring Intel lineup is the AMD Ryzen 7 coming in a few weeks. Early benchmarks show Ryzen beating the pants off of the highest end Intel chips. Promising to ship for a fraction of the cost ($329) and boasting 8 cores with a higher base clock but lower TDP, Ryzen should get serious consideration. This will be ultimately a good thing for Intel and push them to respond in kind upping their game to compete. Who knows, in 2 years I may be rebuilding with AMD.

Credit: AMD
CPU Cooler
Since the mounting of Intel CPUs hasn’t changed enough from the 4th gen CPUs, I was able to reuse my Noctua NH-U12S tower cooler which is designed to support many different mounting requirements. This all copper 6 heat piper cooler has 45MM fins so will not encroach on any memory heat spreader, regardless of height. With the NF-F12 fan attached to the cooler, cold air is pushed across the fins, carrying hot air straight out the back of my case. This remains and excellent part and excellent choice for a SFF Kaby Lake PC build.

Credit: Noctua
Memory
Another reason I wanted to do this build was for the DDR4 upgrade as my Haswell build was DDR3. The memory market is a bit more complicated from the last time I looked at it, with most higher-end vendors playing the same marketing game. Most of the DIMMs available in this space are really 2133MHz DIMMs, but using XMP2 profiles enabled in the BIOS, the modules clock much higher. These modules are marketed using this higher frequency, which is not the default. This is the difference between the 1.2v SPD value of the module and the “tested” value enabled via higher voltage in XMP. What you pay for ultimately is this higher tested speed, a pretty heat spreader and a lifetime warranty. After reading several articles comparing various DDR4 clock speeds across various benchmarks and applications, what is glaringly apparent is that the usefulness of faster memory fits into a very limited use case. In other words, almost no one will truly benefit by paying too much for high clocked RAM. My research showed that 3000MHz is about the sweet spot for DDR4 right now, anything faster is just more expensive with unlikely-to-achieve returns.
Now that said, I was initially sold on a 16GB x 2 kit from the Corsair Vengeance LPX line marketed at 3200MHz. I went with these because Corsair is a well regarded brand and they were priced like a lower clocked pair. I was unable to ever achieve the marketed speed of 3200MHz, the closet I got, stable, was 3100MHz. But to get there I had to overclock the CPU as well. With only XMP enabled on these modules, I was never able to even POST, so I sent them back. There were several other reviews stating the same problem, which I should have heeded. Read the negative reviews and don’t settle for sub-par quality!
My second attempt was a 32GB 3000MHz TridentZ kit from G.Skill, F4-3000C15D-32GTZ. These modules are amazing, not only did the XMP profile take immediately as expected with no CPU OC required, they are quite possibly the most beautiful DIMMs I’ve ever laid eyes on. Pictures really don’t do them justice.

Credit: G.Skill
You’ll notice in the G.Skill spec table below the difference between the SPD and Tested values, these are sold with the tested speeds as you can see on the DIMM label above. Nevertheless, I REALLY like this memory!
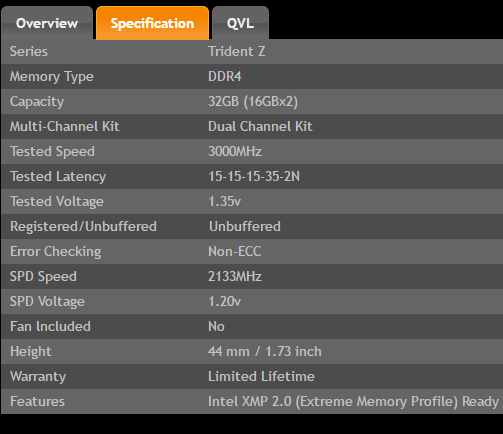
XMP2 profile applied, RAM performing as tested, as expected.

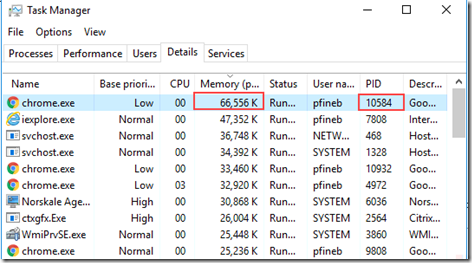
One note on the capacity, how much RAM do you really need? Personally, I leave a ton of stuff open all the time on my PC. 50+ tabs in chrome, word docs, Visio diagrams, RDP sessions etc. I like not having to ever worry about not having enough memory, no matter the workload I need to run. Dishonored 2 itself can use upwards of 8GB all on its own! The other thing I like is not having to use a pagefile which saves wear and tear on my SSDs but also guarantees high performance for all applications. To pull this off, watch the committed value on the memory tab in Task Manager. If this grows anywhere near the amount of physical RAM you have, the pagefile should probably be left enabled. If not, you could disable the pagefile and ease the burden on your SSD.

Data
One the largest motivators for my upgrade this year was moving to Non-Volative Memory Express (NVMe), specifically for the really exciting modules in the new Samsung 960 line. I’ll continue my three-tier model for OS, apps and data, using NVMe for the first two and spinning media for the third. Eventually I’d like to replace the data tier with an SSD, when the time is right. For this build I have a 512GB Samsung 960 Pro for my C drive, a 500GB Samsung 960 Evo for the app drive and a 4TB Seagate BarraCuda 3.5” SATA disk for archive data. These new Samsung NVMe modules are outperforming anything else in this space right now with the following factory performance profiles.
| Module |
Capacity |
Sequential Reads |
Sequential Writes |
| 960 Pro |
512GB |
3500MB/s |
2100MB/s |
| 960 Evo |
500GB |
3200MB/s |
1900MB/s |
These optimistic factory numbers are several times faster than any SSD from any previous build. Crazy! As of this writing, the 512GB Pro module is $330 with the 500GB Evo at $250. Definitely a healthy cost differential for what you may argue is a near negligible performance delta. I wanted, what was perceived, as the fastest NVMe on the market so it seemed worth the price. Capacities on the Pro module go up to 2TB and 1TB on the Evo. The other big difference between these is the Pro modules come with a 5 year warranty vs 3 years on the Evo. These are x4 PCIe 3.0 modules using Samsung’s new famed Polaris controller and 48-layer V-NAND memory.


Credit: Samsung
For local archive data I’m running the 4TB Seagate BarraCuda which is 6Gb SATA and 3.5”. Not a lot to say about this guy, who is a dinosaur in the making.

Credit: Seagate
My basic data scheme goes like this: C: OS only, D: Apps, games and a copy of working data (Dropbox), X: maintains a copy of working data from D and anything else too large or unimportant enough to replicate. Important data is then replicated to a 3rd target: NAS.
Graphics
Upgrading my graphics capability was easily the most noticeable upgrade from my prior build. My previous MSI GTX970 was so solid, I went that way again with a MSI GTX1070 Gaming X 8G. I’m a huge fan of these cards. This one in particular comes with a back plate, 8GB GDDR5 memory @ 8108MHz, a tunable GPU clock and fans that only run when temps exceed 60C (which isn’t very often). The 1080 model gets you higher GPU and memory clocks with more CUDA cores but looking at the benchmarks it barely outperforms its lesser sibling the 1070. I haven’t yet been able to throw anything that this card couldn’t handle at ultra resolution settings, so far Dishonored2, Mafia3 and Dues Ex: Mankind Divided.

Credit: MSI
PSU
Reusing now for its third build in a row, my trusty Silverstone ST55F. Full modularity providing up to 600w max output with a 140mm footprint at 80Plus Gold efficiency… Hard to beat this one, unless your case can’t accept the depth. One step above is the newer ST55F with the platinum efficiency rating. The PP05 short cable kit worked well again and kept cable clutter to a minimum, although I don’t require many cables anymore. And now with the NVMe’s I used a full cable less no longer needing to power 2 extra SATA devices. As always, make sure to check JonnyGuru.com first for thorough and detailed PSU reviews, the ST55F scores very high there.

Credit: Silverstone
Fans
High quality SSO-bearing driven cooling with a low decibel rating and zero vibration is worth the small upcharge. Noctua makes the best fans on the market, so outfitted the entire case. Dual NF-F12 PWM 120mm at the top for downward intake and 1 x NF-A14 140mm fan at the rear for exhaust, in addition to the 120mm NF-F12 on the CPU cooler. I can’t recommend these highly enough.

Credit: Noctua
Case and Complete Build
Once again I built into my BitFenix Phenom M which remains my favorite as easily the best case I’ve ever built with. If you go this route I highly recommend you flip the side panels putting the panel with the buttons and USB ports on the left side of the case instead of the default right side. Otherwise, any time you need to open the case you will have to contend with cords and possibly unplugging cables from a power switch or USB header.

Credit: BitFenix
The Phenom is a mix of steel and soft plastic with the same basic air flow design as the SG09: top down cooling, rear and optional bottom exhaust. This goes against the natural order of things (heat rising) but works very well with 2 x 120mm NF-F12 fans blowing cool air down into the case, directly into the GPU, down into the CPU cooler’s fan blowing across the tower fins and 140mm at the back to exhaust. The GPU breaths cool air, blows it across the PCB and out the rear slot. The rear fan can be either 120mm or 140mm, I opted for the later which is audible at times briefly under load but provides extremely effective cooling. Otherwise this build is silent! The black removable dust filter along the top of the case is the only filtered air input aside from the mesh in the front cover used by the solely PSU, which exhausts downward below the case. The case supports a 120mm radiator, such as the Corsair H80i, if desired. The base section can support dual 120mm fans, a single 200mm fan, or 2 x 3.5” HDDs. The case also comes with a removable heat shield underneath to prevent exhaust heat from the PSU getting sucked back into the case. Lots of different configurations are possible with this case which is fantastic!
The image below shows my completed build and illustrates the airflow scheme per my design selections. Ultimately this case works extremely well and keeps all components well cooled. There aren’t a lot of nooks to tuck cables into in this case so bundling is about as good as it gets which is complicated when using shorter cables. The key is to not block any airflow with the bundle.

CPU Performance
The tools I used to benchmark CPU are PassMark PerformanceTest 9 and Cinebench. The CPU Mark results with the 2 reference parts tells the tale, there is only a very small incremental gain over my previous 4790K. The gain is even smaller from the reference 6700K Skylake part, reinforcing the fact that if you own Skylake now, there is really no point at all upgrading to Kaby Lake. My results for all components ranked within the 99th percentile according to PassMark.

Similar story on Cinebench but as is the case with all the benchmarks, there’s a ton of variance and a wide spread in the scores.

Memory Performance
For the Memory Mark I included a few other high-end PC builds with varying memory speeds. Not sure how useful this bench is honestly due to that top result on slower DDR3, shown below. Generally not a lot of variance here further suggesting that paying for higher RAM clocks is probably not worth it.

Graphics Performance
At the time I bought my new MSI GTX 1070 Gaming X board, the benchmarks showed this card barely below the top dog 1080, but for a significant cash savings. Coming from the 970, the 1070 is improved in every way with more memory, more cores, higher clocks and higher supported resolutions (4K). There was nothing my prior 970 couldn’t handle, as long as I had my games properly optimized, which meant a setting quality, at best, to “high”. With the 1070 I can run very intensive titles like Dishonored 2 at Ultra settings with no trouble at all.
+3500 points in the 3D graphics mark test:

Old vs new on the Unigine Heaven bench, pretty significant difference even running the 1070 a step higher at Ultra:


960 Pro vs 960 Evo
Ok prepared to be amazed, here are the 960’s in action. This test consists of running a simple Crystal Disk Mark bench while monitoring IOPS with Perfmon. The 960 Pro generates nearly 200,000 read IOPS while clocking a staggering 3255 MB/s, which as amazing as that is, is actually much lower than what this part should be capable of!

Writes clock in around 140,000 IOPS with 1870MB/s on the 32 queues sequential test.

The highest numbers I observed in these tests were 3422MB/s reads and 1990MB/s writes. Impressive, but still below the advertised 3500/ 2100MB/s and the performance of this module is not nearly as consistent as it should be.The 960 Evo is no slouch either and actually outperforms the Pro in these tests!! This definitely should not be the case.
Running the same bench, the 960 Evo generated 203,000 IOPS while pushing 3335 MB/s. This is higher than the Pro module in both areas.

Reads are also impressive here and while the Evo doesn’t beat the Pro in MB/s, it does clock in 13,000 IOPS higher.

Running the benchmark within Samsung Magician draws an even starker picture. The Evo absolutely kills the Pro in read performance but the Pro wins the write bench by a small margin. These results should not be.

In light of this, the Pro module is going back, I’ll update this post with new numbers once I receive my replacement part. If the replacement doesn’t perform, it too will be going back to be replaced by another Evo module instead. As is stands, the Evo’s performance is very predictable, uncomfortably close to the Pro and for $65 less it may be the better buy, if you don’t mind a shorter 3 year warranty.
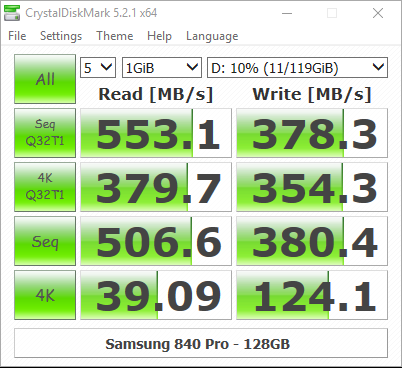
Just for comparison, here is the DiskMark for my older Samsung 840 Pro which is a solidly performing SSD:
Temps & Power Consumption
Even with my case’s upside-down airflow design, it does a good job keeping things cool. This is also in no small part due to the incredible Noctua fans which are literally the best you can buy and well worth it. I run my PC using the default Balanced power plan which allows the CPU to throttle down during idle or low activity periods. At idle with fans running at low speeds and the core voltage at .7v, the CPU chirps along at a cozy 38C with the fans barely spinning.

Under benchmark load with the CPU pegged at 100%, temps shift between low 50s to low 60’s with fans shifting their RPMs upward in kind. I touched 66 a couple of times but couldn’t capture the screenshot. 63 degrees under load I’d say is very good for this CPU! Once the Arctic Silver 5 thermal compound breaks in completely this should get a touch better.

During the PassMark bench I recorded the temps, voltage and frequency as shown below. Here you can see the full affect of the Kaby Lake stock Turbo in play with the CPU running its max clock of 4.5GHz. 55 degrees recorded with the fans at less than 50%. You can also see the XMP2 profile in affect with the RAM clock at 3000MHz.

I recorded power draw at idle and under load with a heavy graphics bench, where the PC will draw its highest wattage with the GPU thirstily slurping juice. At its lowest observed reading with absolutely nothing happening, I recorded 41W at the wall. Very efficient.

Under the heavy graphics bench, the highest reading I observed was 244w at the wall. As it stands, given my components, their power draw and my hungriest graphical workload, my 550W PSU is more than sufficient for this build.

Build Summary
All in all this is a pretty exciting year to build a high-end PC with loads of improvements available in graphics and disk.
| Motherboard |
Asus Z270M-Plus |
$150 |
| CPU |
Intel Core i7-7700K |
$379 |
| CPU Cooler |
Noctua NH-U12S |
(reuse) |
| Memory |
G.Skill TridentZ |
$200 |
OS NVME
Apps NVMe
Data HDD |
Samsung 960 Pro
Samsung 960 Evo
Seagate Baracuda |
$330
$250
$130 |
| Graphics |
MSI GTX 1070 Gaming X |
$399 |
| PSU |
Silverstone SST-ST55F-G |
(reuse) |
| Fans |
Noctua NF-F12 PWM
NF-A14 PWM |
(reuse) |
| Case |
BitFenix Phenom M |
(reuse) |
| OS |
Window10 Pro |
|
| Monitors |
2 x Dell U2415b |
(reuse) |
| Mouse & Keyboard |
Corsair M65/ K70 |
(reuse) |
| Total invested |
|
$1838 |























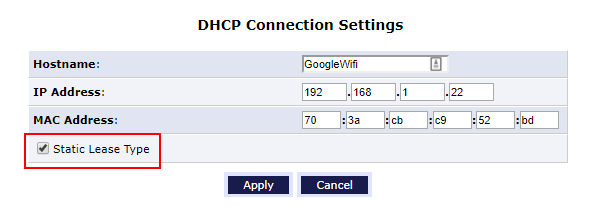

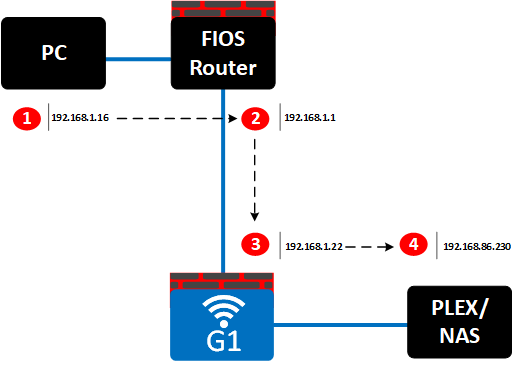

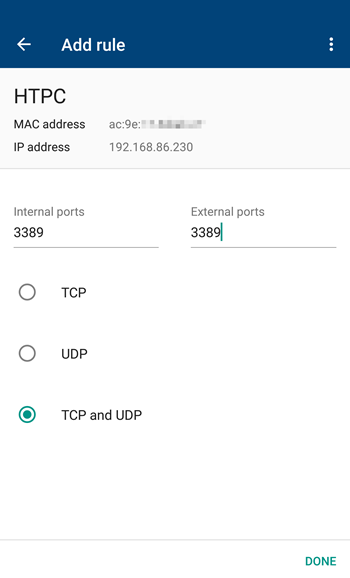

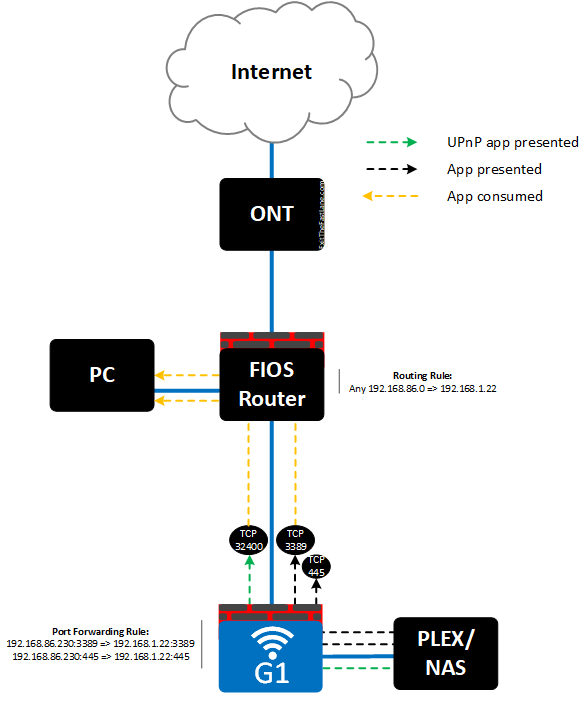

















![image_thumb[3]](https://lh3.googleusercontent.com/-C22pzG0s0_c/WOgANobWEiI/AAAAAAAAP8o/TKjI3ce7xwU/image_thumb3%25255B1%25255D.png?imgmax=800 "image_thumb[3]")
![image_thumb[4]](https://lh3.googleusercontent.com/-TuQ4uZ3fLnk/WOgAOnBD5tI/AAAAAAAAP8s/KytmcLurOzY/image_thumb4%25255B1%25255D.png?imgmax=800 "image_thumb[4]")
![image_thumb[5]](https://lh3.googleusercontent.com/-28QnsVSyRa8/WOgAPZdHPyI/AAAAAAAAP8w/g2pBGkr4y7A/image_thumb5%25255B1%25255D.png?imgmax=800 "image_thumb[5]")
![image_thumb[6]](https://lh3.googleusercontent.com/-ifa1JyfHK1o/WOgAQB0EhlI/AAAAAAAAP80/2qFDUlxNO_I/image_thumb6%25255B1%25255D.png?imgmax=800 "image_thumb[6]")
![image_thumb[8]](https://lh3.googleusercontent.com/-XmjdbyYgc88/WOgAQ4-hpgI/AAAAAAAAP84/llX_HHevZdc/image_thumb8%25255B1%25255D.png?imgmax=800 "image_thumb[8]")

























![image_thumb[1]](https://lh3.googleusercontent.com/-CFhZjiWn1Cs/WOf-WZFYd2I/AAAAAAAAP8Y/I95Rtf0SqBo/image_thumb11%25255B1%25255D.png?imgmax=800)