
You’ll be hearing a lot more about Dell EMC ScaleIO in the coming months and years. ScaleIo is a Software Defined Storage solution from Dell EMC that boasts massive flexibility, scalability and performance potential. It can run on nearly any hardware configuration from any vendor, all-flash or spinning disk, as well as supports XenServer, Linux and VMware vSphere. Like most other SDS solutions, ScaleIO requires a minimum of three nodes to build a cluster but unlike most others, ScaleIO can scale to over 1000 nodes in a single contiguous cluster. ScaleIO uses a parallel IO technology that makes active use of all disks in the cluster at all times to process IO. This performance potential increases as you scale and add nodes with additional disks to the cluster. This translates to every VM within the cluster being able to leverage the entire available performance profile of every disk within the cluster. Limits can be imposed, of course, to prevent any single consumer from draining all available IO but the greater potential is immense.
Key Features
- Tiering – Unlike most SDS offers available, ScaleIO requires no tiering. For an all-flash configuration, every SSD in every node is completely usable. DAS Cache is required on hybrid models for write-back caching. It should also be noted that for hybrid configurations, each disk type must be assigned to separate volumes. There is no mechanism to move data from SSD to HDD automatically.
- Scalability – 3 nodes are required to get started and the cluster can scale to over 1000 nodes.
- Flexibility – Software solution that supports all hardware, all major hypervisors. Able to be deployed hyper-converged or storage only.
- Data protection – two-copy mirror mesh architecture eliminates single points of failure.
- Enterprise features – QOS, thin provisioning, snapshotting.
- Performance – Parallel IO architecture eliminates disk bottlenecks by using every disk available in the cluster 100% of the time. The bigger you scale, the more disks you have contributing capacity and parallel IO. This is the ScaleIO killer feature.
ScaleIO Architecture
ScaleIO can be configured in an all-combined Hyper-converged Infrastructure (HCI) model or in a traditional distributed storage model. The HCI variant installs all component roles on every node in the cluster with any being able to host VMs. The distributed storage model installs the server pieces on dedicated infrastructure utilized for presenting storage only. The client consumer pieces are then installed on separate compute-only infrastructure. This model offers the ability to scale storage and compute completely separately if desired. For this post I’ll be focusing on the the HCI model using Citrix XenServer. XenServer is a free to use open source hypervisor with a paid support option. It doesn’t get much easier than this with XenServer running on each node and XenCenter running on the admin device of your choosing. There is no additional management infrastructure required! ScaleIO is licensed via a simple $/TB model but too can be used in trial mode.
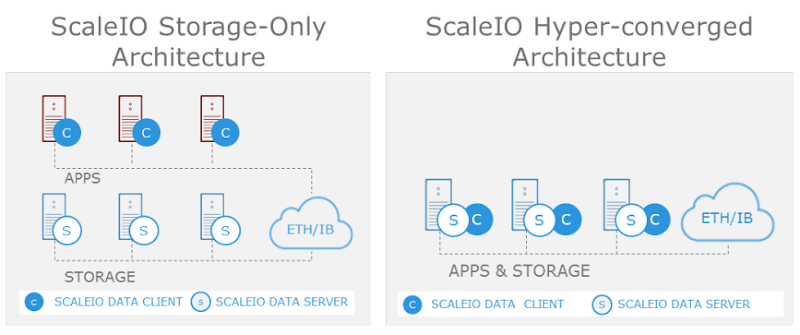
The following are the primary components that comprise the ScaleIO architecture:
- ScaleIO Data Client (SDC) – Block device driver that runs on the same server instance as the consuming application, in this case VMs. In the HCI model all nodes will run the SDC.
- ScaleIO Data Server (SDS) – Not to be confused with the general industry term SDS, “SDS” in the ScaleIO context is a server role installed on nodes that contribute storage to the cluster. The SDS performs IOs at the request of the SDCs. In the HCI model all nodes will run the SDS role.
- Metadata Manager (MDM) – Very important role! The MDM manages the device mappings, volumes, snapshots, storage capacity, errors and failures. MDM also monitors the state of the storage system and initiates rebalances or rebuilds as required.
- The MDM communicates asynchronously with the SDC and SDS services via a separate data path so to not affect their performance.
- ScaleIO requires at least 3 instances of the MDM: Master, Slave and Tie-Breaker.
- A maximum of 5 MDM roles can be installed within a single cluster: 3 x MDMs + 2 x tie-breakers.
- Only one MDM Master is active at any time within a cluster. The other roles are passive unless a failure occurs.
- ScaleIO Gateway – This role includes Installation Manager for initial setup as well as the REST Gateway and SNMP trap sender. The Gateway can be installed on the ScaleIO cluster nodes or an external management node.
- If the gateway is installed on a Linux server, it can only be used to deploy ScaleIO to Linux hosts.
- If the gateway is installed on a Windows server, it can be used to deploy ScaleIO to Linux or Windows hosts.
- XenServer, based on CentOS, fully qualifies as a “Linux host”.
Once the ScaleIO cluster is configured, all disks on each host are assigned to the SDS local to that host. Finally volumes are created and mounted as consumable to applications within the cluster.
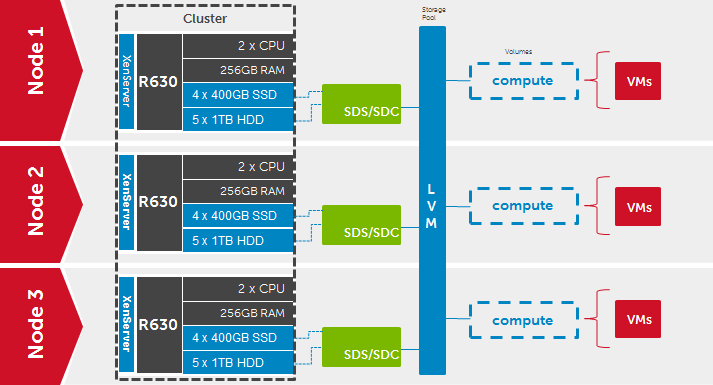
The diagram below illustrates the relationship of the SDC and SDS roles in the HCI configuration:

My Lab Environment:
- 3 x Dell PowerEdge R630
- Dual Intel E5-2698v4
- 512GB RAM
- 480GB Boot SSD
- 4 x 400GB SSDs
- 5 x 1TB (7.2K RPM)
- 2 x 10Gb NICs
- XenServer 6.5
- ScaleIO 2.0
- XenDesktop 7.11
- I also used a separate Windows server on an old R610 for my ScaleIO Gateway/ Installation Manager
Here is the high-level architecture of my deployment. Note that there is a single compute volume which is mounted locally on each host via the XenServer Pool, so depicted below as logical on each:
Prep
As of this writing, XenServer 7.0 is shipping but 6.5 is the currently supported version by ScaleIO. The deployment steps for 7.0 should be very similar once officially supported. First install XenServer on each node, install XenCenter on your PC or management server, create a new pool, add all nodes to XenCenter, create a pool and fully patch each node with the XenCenter integrated utility. If the disks installed in your nodes have any prior formatting this needs to be removed in the PERC BIOS or via the fdisk utility within XenServer.
Now would be a good time to increase the memory available to Dom0 to the maximum 4GB, especially if you plan to run more than 50 VMs per node. From an SSH session or local command shell, execute:
/opt/xensource/libexec/xen-cmdline --set-xen dom0_mem=4096M,max:4096M
Install the packages required for ScaleIO on each node: numactl and libaio. OpenSSL needs to be updated to 1.0.1 using the XenCenter update utility via Hotfix XS65ESP1022.
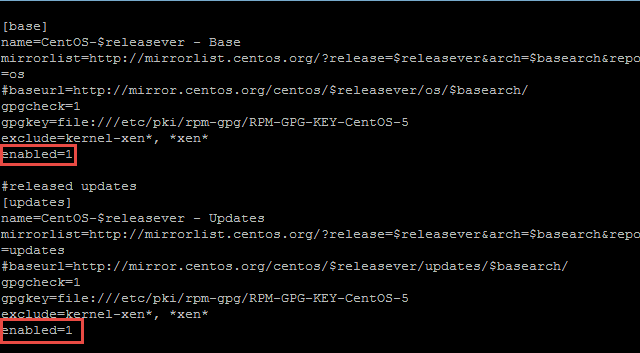
Libaio should already be present but before numactl can be added, the repositories will need to be edited. Open the base repository configuration file:
vi /etc/yum.repos.d/CentOS-Base.repo
Enable the Base and released updates repositories changing “enabled=0” to “enabled=1”. Save the file, :wq
Next install numactl, libaio should report as already installed, nothing to do. Repeat this on each node.
yum install numactl
ScaleIO Installation
Download all the required ScaleIO files: Gateway for Windows or Linux, as well as all the installation packages for ScaleIO (SDC, SDS, MDM, xcache, and lia). Install the ScaleIO Gateway files, either for Windows to do an external remote deployment, or for Linux to install the gateway on one of the XenServer nodes. For this installation I used an external Windows server to conduct my deployment. The ScaleIO Gateway installation for Windows has two prerequisites which must be installed first:
- Java JRE
- Microsoft Visual C++ 2010 x64 Redist
Next run the gateway MSI which will create a local web instance used for the remainder of the setup process. Once complete, in the local browser connect to https://localhost/login.jsp, and login using admin plus the password you specified during the Gateway setup.
Once logged in, browse to and upload the XenServer installation packages to the Installation Manager (installed with the Gateway).
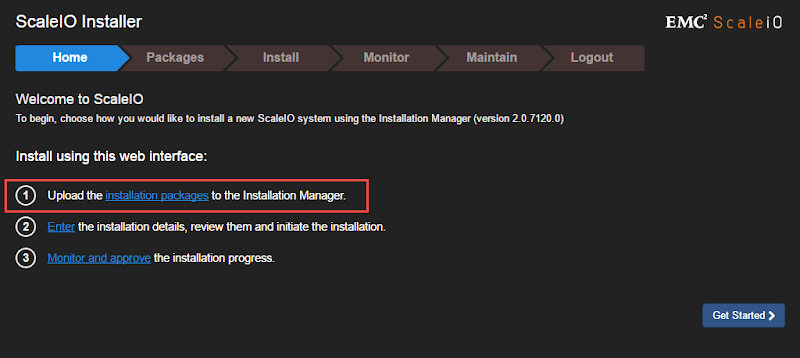
Here you can see that I have the ScaleIO installation packages for Xen 6.5 specifically.
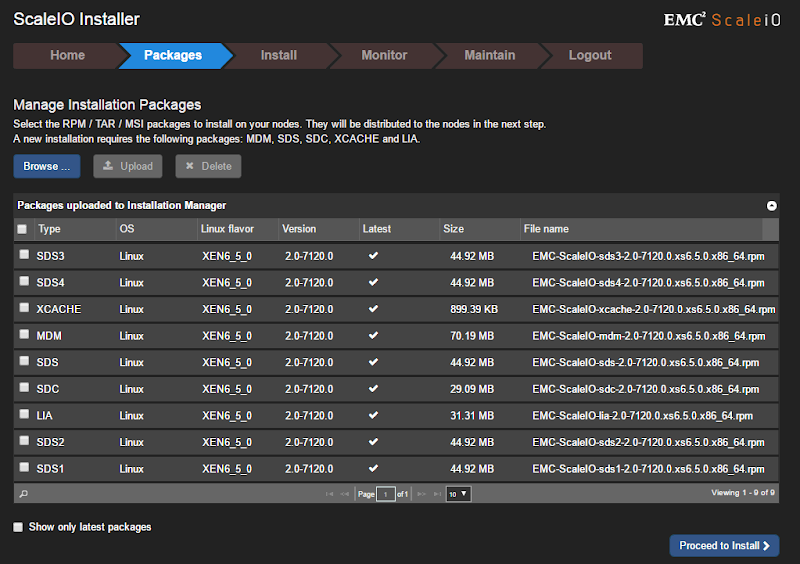
Once ready to install, you will be presented with options to either upload an installation CSV file, easier for large deployments, or if just getting started you can select the installation wizard for 3 or 5-node clusters. I will be selecting the wizard for 3-nodes.
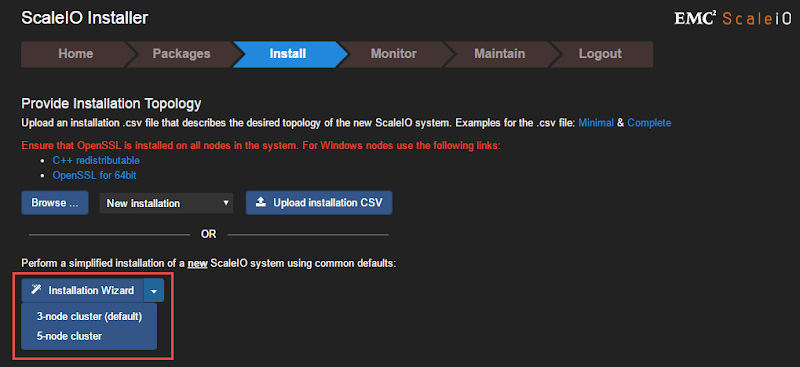
Specify the passwords for MDM and LIA, accept the EULA, then enter IP addresses and passwords for the mandatory three MDM instances at the bottom. The IP addresses at the bottom should be those of your physical XenServer nodes. Once all information is properly entered, the Start Installation button will become clickable. If you did not install the 1.0.1 OpenSSL patch earlier, this step will FAIL.
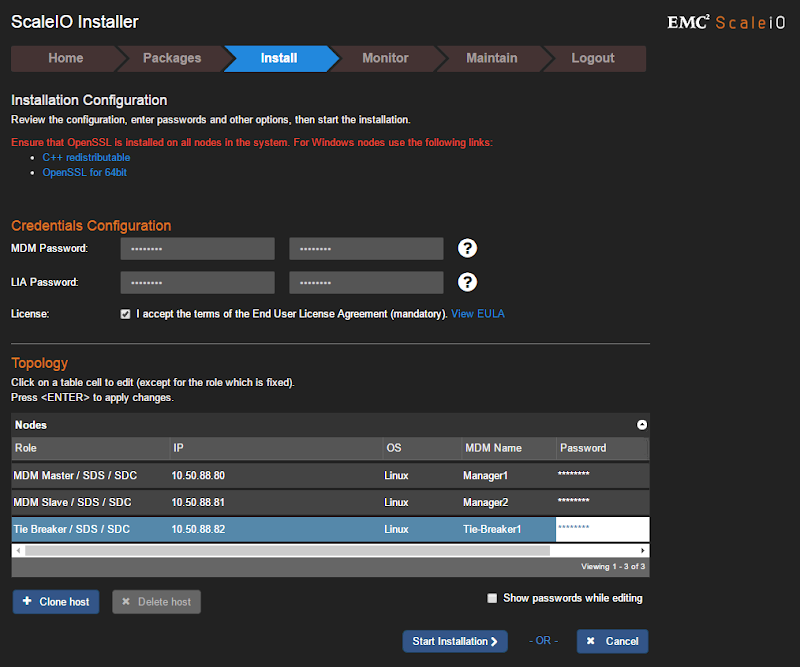
Several phases will follow (query, upload, install, configure) which should be initiated and monitored from the Monitor tab. You will be prompted to start the following phase assuming there were no failures during the current phase. Once all steps complete successfully, the operation will report as successful and can be marked as complete.
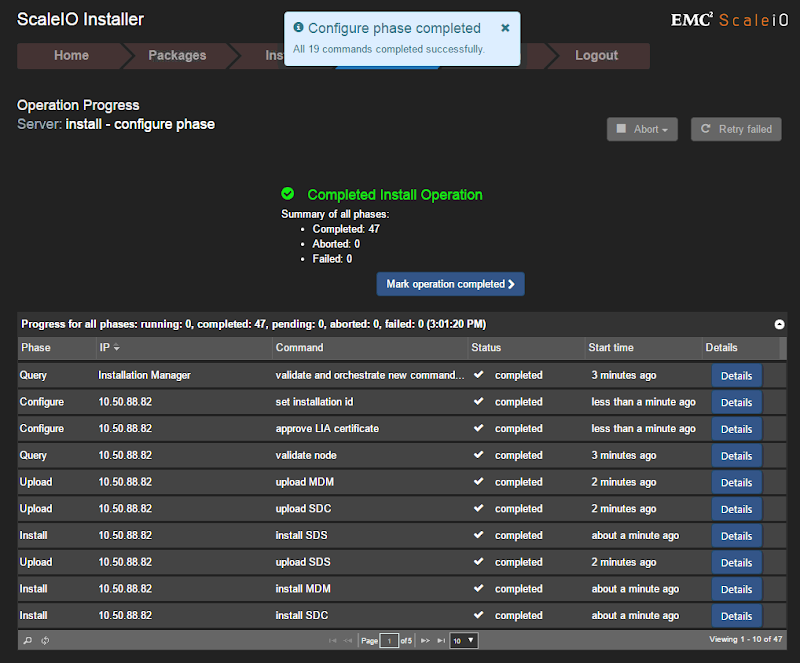
ScaleIO Configuration
Next install then open the ScaleIO GUI on your mgmt server or workstation and connect to master MDM node configured previously. The rest of the configuration steps will be carried out here.
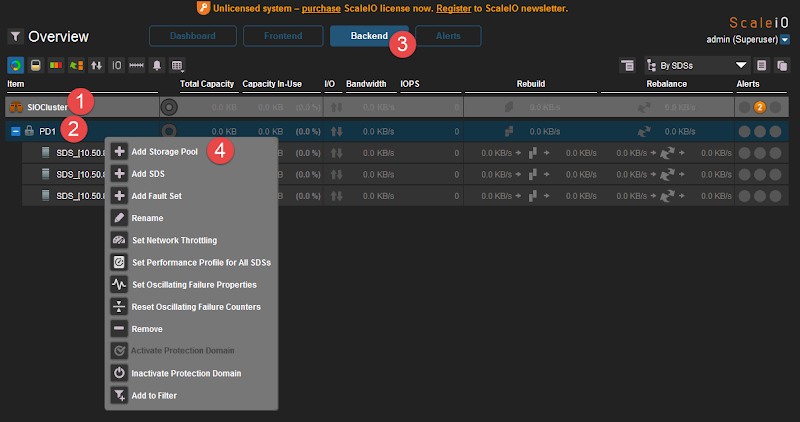
First thing, from the Backend tab, rename your default system and Protection Domain names to something of your choosing. Then create a new storage pool or rename the default pool.
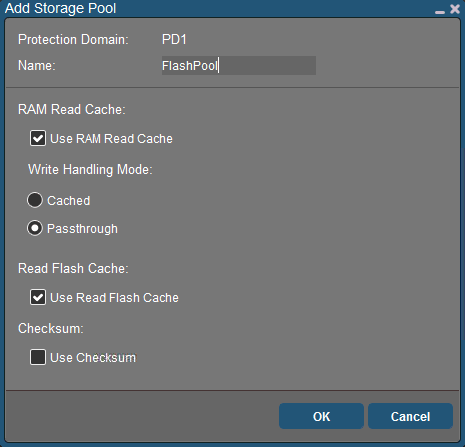
I’m naming my pools based on the disk media, flash and spinning. Create the pool within the Protection Domain, give it a name and select the caching options as appropriate.
Before we can build volumes we need to assign each disk to each SDS instance running on each node. First identify the disk device names on each host via SSH or local command shell by running:
fdisk -l
Each device will be listed as /dev/sdx. Right-click the first SDS on the first node and select Add Device. In the dialog that follows, add each local disk on this node, assign it to the appropriate pool and name it something meaningfully unique. If your disk add operation fails here, you probably have previous formatting on your disks which needs to be removed first using fdisk or the PERC BIOS! You can add both SSD and HDD devices as part of this operation.
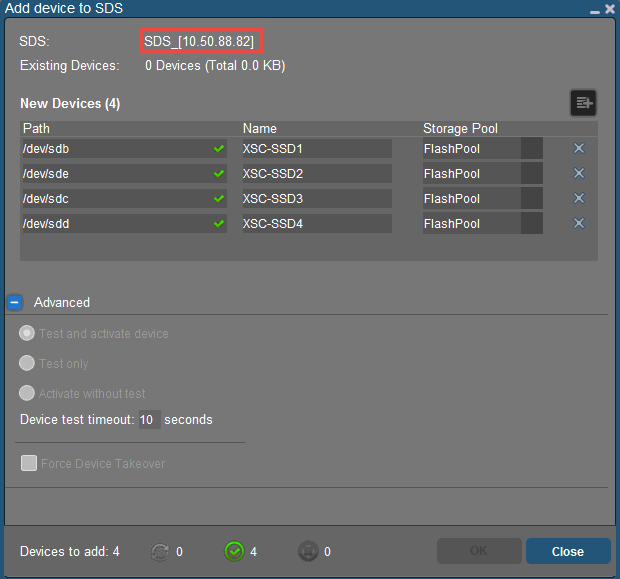
Once this has been successfully completed for each node, you will see all disks assigned to each SDS in the GUI along with the total capacity contributed by each. You’ll notice that the circular disk icons next to each line are empty, because so are the disks at the moment.
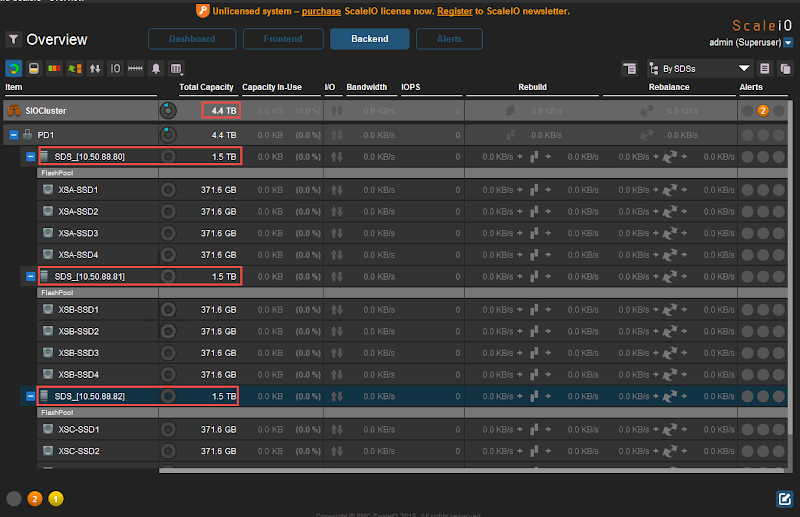
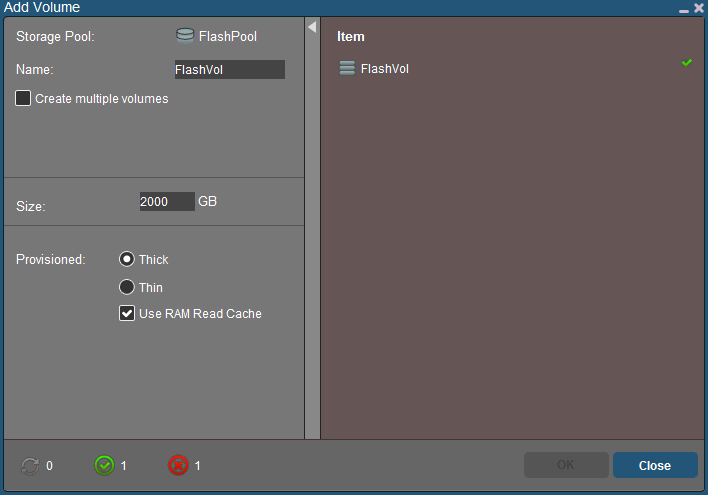
Now keep in mind that ScaleIO is a mirror mesh architecture, so only half of that 4.4TB capacity is usable. From the Frontend tab, right-click the Storage Pool and create a new volume with this in mind. I’m using thick provisioning here for the sake of simplicity.
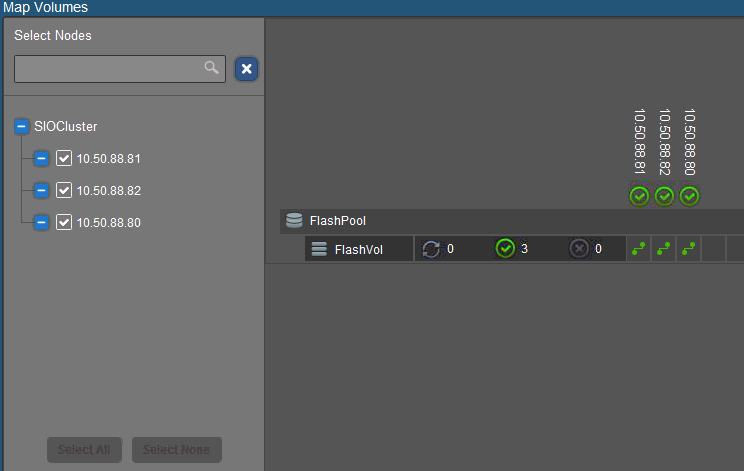
Once the volume is created, map it to each SDC which will make it available as a new disk device on each node. Right-click the volume you just created and select Map Volumes. Select all hosts then map volumes.
If you run fdisk -l now, you will see a new device called /dev/scinia. The final step required before we can use our new storage is mounting this new device on each host which only needs to be done once if your hosts are configured in a Pool. By default the XenServer LVM is filtering so does not see our ScaleIO devices called “scini”. Edit the lvm configuration file and add this device type as highlighted below. Pay particular care to the text formatting here or LVM will continue to ignore your new volumes.
vi /etc/lvm/lvm.conf
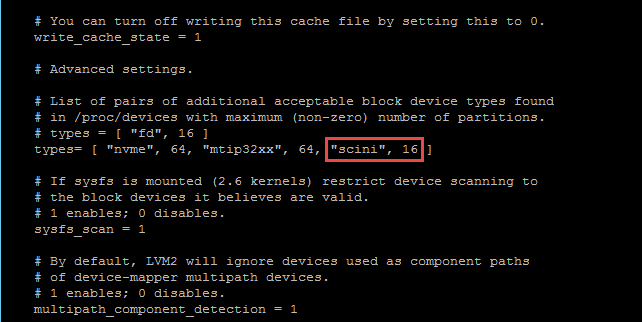
Next confirm that LVM can see the new ScaleIO device on each node, run:
lvmdiskscan
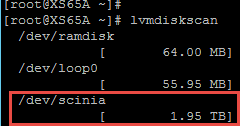
Now it’s time to create the XenServer Storage Repository (SR). Identify the UUIDs of the ScaleIO volumes presented to a host and identify the UUID of the host itself, just pick a host from the pool to work with. You will need the output of both of these commands when we create the SR.
ls -l /dev/disk/by-id | scinixe host-list
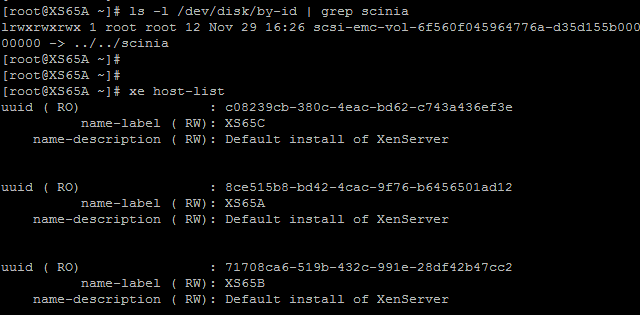
This next part is critical! Because ScaleIO presents storage as a block device, specifically as an LVM, all thin provisioning support will be absent. This means that all VMs deployed in this environment will be full thick clones only. You can thin provision on the ScaleIO backend but all blocks must be allocated to your provisioned VMs. This may or may not work for your scenario but for those of you paying attention, this knowledge is your reward. 🙂
Another very important consideration is that you need to change the “name-label” value for every SR you create. XenServer will allow you to create duplicate entries leaving you to guess which is which later! Change the portions in red below to match your environment.
xe sr-create content-type="ScaleIO" host-uuid=8ce515b8-bd42-4cac-9f76-b6456501ad12 type=LVM device-config:device=/dev/disk/by-id/scsi-emc-vol-6f560f045964776a-d35d155b00000000 shared=true name-label="SIO_FlashVol"
This command will give no response if successful, only an error if it wasn’t. Verify that the volumes are now present by looking at the Pool storage tab in XenCenter. Creating this SR on one host will enable access to all within the pool.
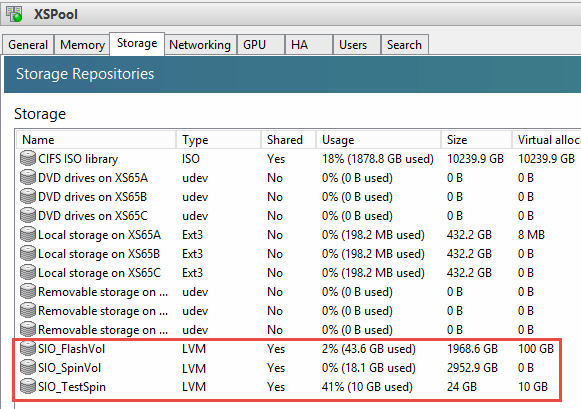
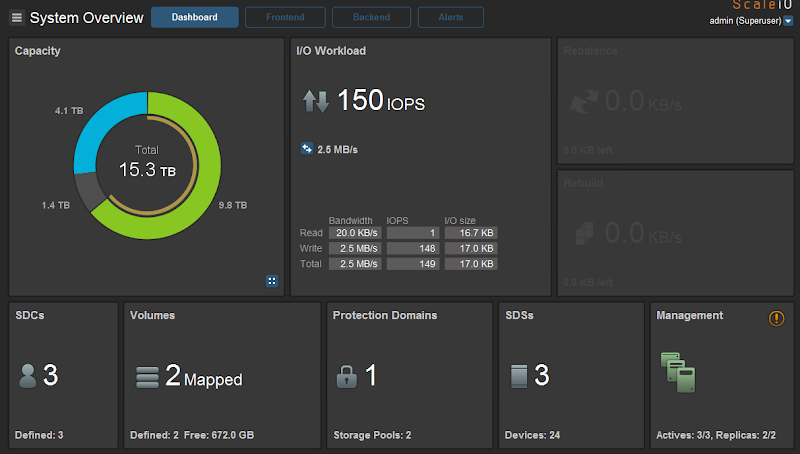
Now the disk resources are usable and we can confirm on the ScaleIO side of things by going back to the dashboard in the ScaleIO GUI. Here we can see the total amount of raw storage in this cluster, 15.3TB, the spare amount is listed in blue (4.1TB), the thin yellow band is the volume capacity with the thicker green band behind it showing the protected capacity. Because I’m using thick volumes here, I only have 1.4TB unused. The rest of the information displayed here should be self-explanatory.
ScaleIO & XenDesktop
Since we’re talking about Citrix here, I would be remiss if I didn’t mention how XenDesktop works in a ScaleIO environment. The setup is fairly straight-forward and since we’re using XenServer as the hypervisor, there is no middle management layer like vCenter or SCVMM. XenDesktop talks directly to XenServer for provisioning, which is awesome.
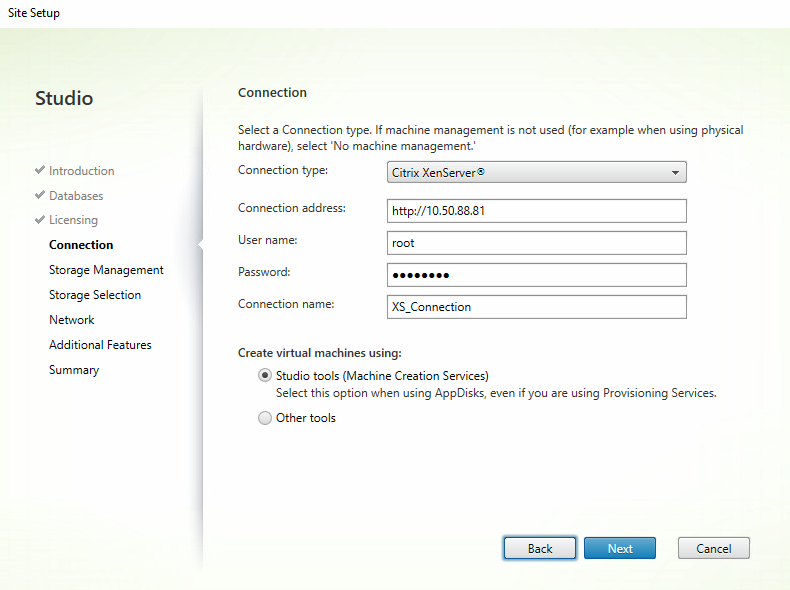
If running a hybrid configuration, you can separate OS and Temporary files from PvDs, if desired. Here I’ve placed my PvD’s on my less expensive spinning volume. It’s important to note that Intellicache will not work with this architecture!

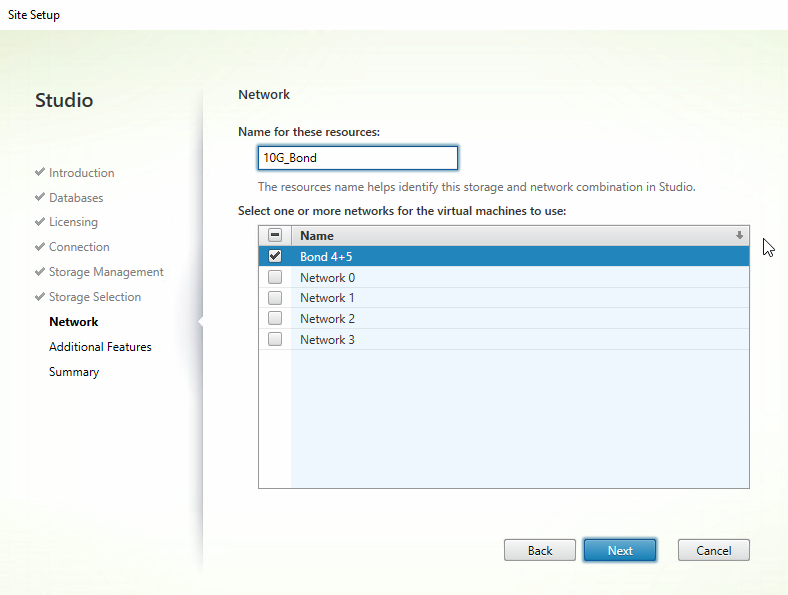
Select the VM network which should be a bond of at least 2 NICs that you created within your XenServer Pool. If you haven’t done this yet now would be a good time.
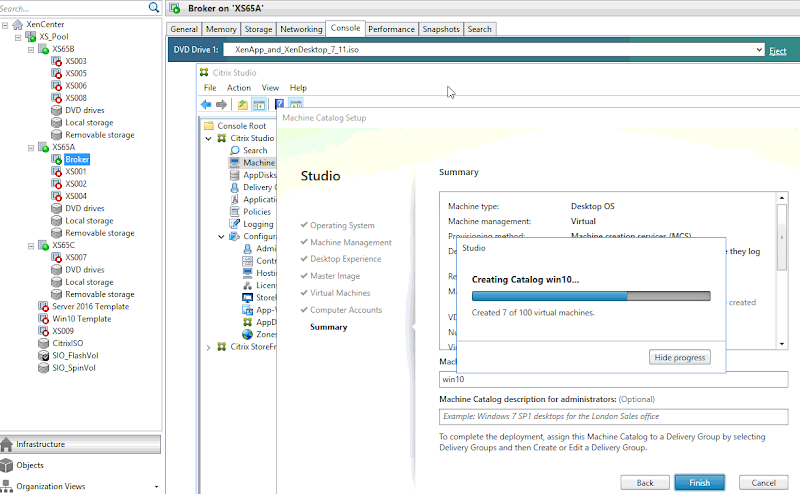
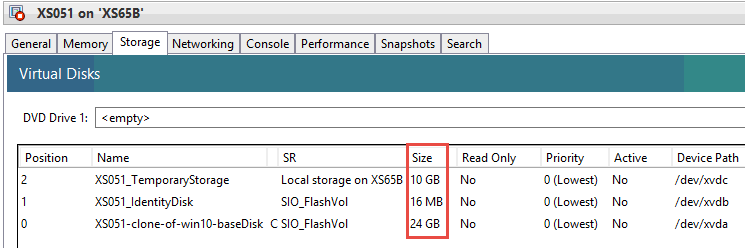
Finish the setup process then build a machine catalog using a gold master VM that you configured and shut down previously. I’ve configured this catalog for 100 VMs with 2GB RAM and 10GB disk cache. The gold master VM has a disk size of 24GB. Here you can see my catalog being built and VMs are being created on each host in my pool.
This is where things get a bit…sticky. Because ScaleIO is a block device, XenServer does not support the use of thin provisioning, as mentioned earlier. What this means is that the disk saving benefits of non-persistent VDI will be absent as well. Each disk image, PvD and temporary storage allocated to each VM in your catalog will consume the full allotment of its assignment. This may or may not be a deal breaker for you. The only way to get thin provisioning within XenServer & XenDesktop is by using shared storage presented as NFS or volumes presented as EXT3, which in this mix of ingredients, applies to local disk only. In short, if you choose to deploy VDI on ScaleIO using XenServer, you will have to use thick clones for all VMs.
Performance
Lastly, a quick note on performance, which I tested using the Diskspd utility from Microsoft. You can get very granular with diskspd to model your workload, if you know the characteristics. I ran the following command to model 4K blocks weighted at 70% random writes using 4 threads, cache enabled, with latency captured.
Diskspd.exe -b4k -d60 -L -o2 -t4 -r -w70 -c500M c:\io.dat
Here’s the output of that command real time from the ScaleIO viewpoint to illustrate performance against the SSD tier. Keep in mind this is all being generated from a single VM, all disks in the entire cluster are active. You might notice the capacity layout is different in the screenshot below, I reconfigured my protection domain to use thin provisioning vs thick when I ran this test.

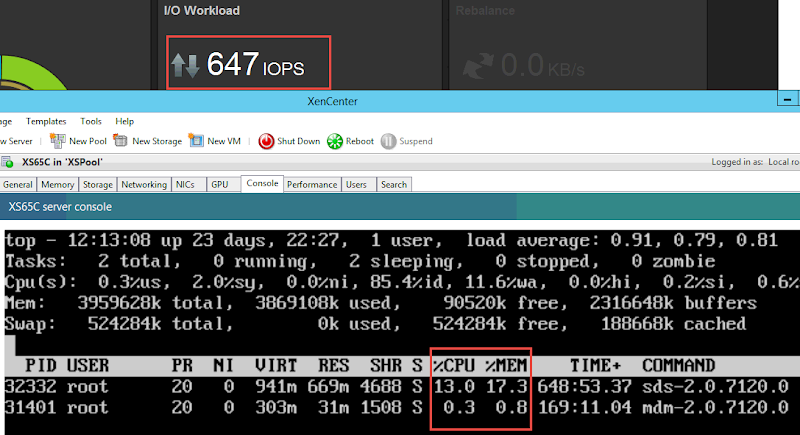
Here is a look at the ScaleIO management component resource consumption during a diskspd test against the spinning tier generated from a single VM. Clearly the SDS role is the busiest and this will be the case across all nodes in the cluster. The SDC doesn’t generate enough load to make it into Top plus it changes its PID every second.
Closing
There are a lot of awesome HCI options in the market right now, many from Dell EMC. The questions you should be asking are: Does the HCI solution support the hypervisor I want to run? Does the HCI solution provide flexibility of hardware I want to run? And, is the HCI solution cost effective? ScaleIO might be perfect for your use case or maybe one of our solutions based on Nutanix or VSAN might be better suited. ScaleIO and XenServer can provide a massively scalable, massively flexible solution at a massively competitive price point. Keep in mind the rules on usable disk and thin provisioning when you go through your sizing exercise.


















































































