As I called out in my vSphere 5.5 upgrade post, the vSphere Client is now deprecated in 5.5 so in preparation of an inevitable future, I’m forcing myself to use the Web Client to gain familiarity. Turns out there was way more moving around than I initially thought so I’m selfishly documenting a few pertinent items that seemed less than intuitive to me my first time through. Some things are just easier to do in the legacy vSphere Client, or maybe I’m just too accustomed after 3 generations of ESX/i. In any case, I encourage you to use the web client as well and hopefully these tips will help.
Topics covered in this post:
- How to configure iSCSI software adapters
- How to add datastores
- How to manage multipathing
- How to rename an ESXi host
- Cool changes in Recent Tasks pane
- Traffic Shaping
- Deploying vCenter Operations Manager (vCOps)
How to configure iSCSI software adapters:
This assumes that the preliminary steps of setting up your storage array and requisite physical networking have already been properly completed. The best and easiest way to do this is via dedicated switches and server NICs for iSCSI in a Layer2 switch segment. Use whatever IP scheme you like, this should be a closed fabric and there is no reason to route this traffic.
First things first, if you don’t have a software iSCSI adapter created on your hosts, create one in the Storage Adapters section of Storage Management for a particular ESXi host. Once created, it will appear in the list below. A quick note on software vs hardware iSCSI initiators. Physical initiators can generally do iSCSI offload OR jumbo frames. not both. We have seen the use of jumbo frames to be more impactful to performance than iSCSI offload, so software initiators with jumbo frames enabled is the preferred way to go here.

Click over to the Networking tab and create a new vSwitch with a VMkernel Network Adapter for iSCSI.

Choose the physical adapters to be used in this vSwitch, create a useful network Port Group label such as iSCSI-1 and assign an IP address that can reach the storage targets. Repeat this process and add a second VMkernel adapter to the same vSwitch. Configure your VMK ports to use apposing physical NICs. This is done by editing the port group settings and changing the Failover order. This allows you to cleanly share 2 physical NICs for 2 iSCSI connections within a single vSwitch.

In my case VMK2 is active on vmnic3 and VMK3 is active on vmnic1 providing physical path redundancy to the storage array.

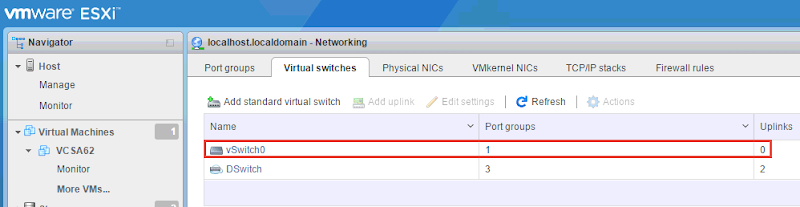
When all is said and done, your vSwitch configuration should look something like this:

Next under the iSCSI software adapter, add the target IP to your storage (group IP for EqualLogic). Authentication needs and requirements will vary between organizations. Choose and configure this scheme appropriately for your environment. For my lab, I scope connections based on subnet alone which defines the physical Layer2 boundary of my iSCSI fabrics.

Next configure the network port binding to ensure that the port groups you defined earlier get bound to the iSCSI software adapter using the proper physical interfaces.

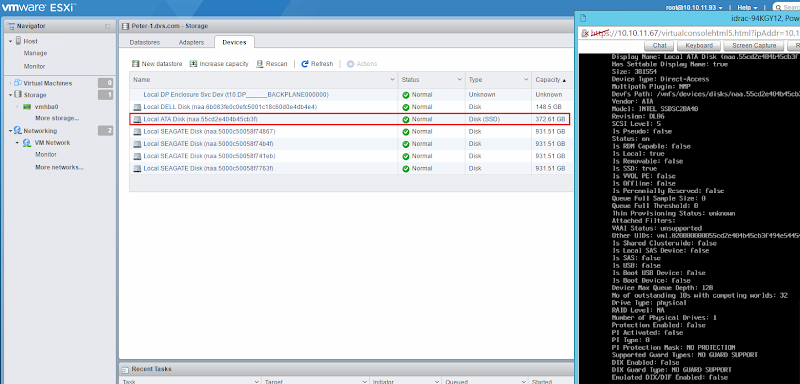
At this point, if you have any volumes created on your array and presented to your host, a quick rescan should reveal the devices presented to your host as LUNs.

You should also see 2 paths per LUN (device) per host based on 2 physical adapters connecting to your array. EqualLogic is an active/passive array so only connections to the active controller will be seen here.

If you run into trouble making this work after these steps, jump over to the vSphere Client which does make this process a bit easier. Also keep in mind that all pathing will be set to Fixed by default. See my How to manage multipathing topic below for guidance on changing this.
iSCSI works very well with jumbo frames which is an end-to-end Layer2 technology, so makes sure a MTU of 9000 is set on all ESXi iSCSI vSwitches, VMK ports, as well as the NICs on the storage array. Your switches must be capable of supporting jumbo frames as well. This will increase the performance of your iSCSI network and front-end storage operation speeds.

How to add datastores:
Once your new datastore has been provisioned from your storage platform and presented to your ESXi hosts, from the Hosts and Clusters view, navigate to Related Objects then datastores. From here click the Create a new Datastore button.

Choose the host or cluster to add the datastore to, choose whether it is NFS or VMFS, name the datastore and choose a host that can see it. You should see the raw LUN in the dialog below.

Choose the VMFS version and any partition options you want to implement. Confirm and deploy.

If presenting to multiple hosts, once the VMFS datastore is created and initialized on one, they all should see it assuming the raw device is present via a previous adapter rescan.
How to manage multipathing:
From the Hosts and clusters view, click the Storage tab, choose the datastore you want to manage, click Manage in the middle pane then click Connectivity and Multipathing under Settings.
 Alternatively, from the Hosts and Clusters view (from any level item), navigate to Related Objects, then Datastores. Either click the volume you want to edit or choose Settings from the dropdown. Either method will get you to the same place.
Alternatively, from the Hosts and Clusters view (from any level item), navigate to Related Objects, then Datastores. Either click the volume you want to edit or choose Settings from the dropdown. Either method will get you to the same place.

From the datastore Settings page, click Manage and under Settings (once again) click Connectivity and Multipathing. In the middle of the screen you should see all hosts attached to whatever datastore you selected. Clicking on each host will reveal the current Path Selection Policy below, “Fixed” by VMware default along with the number of paths present per host.

To change this to Round Robin, click Edit Multipathing, change the Path Selection Policy, repeat for each host connected to the datastore.

How to rename an ESXi host:
Renaming hosts is one area that the Web Client has made significantly easier (once you figure out where to go)! Select a host from the Hosts and Clusters view, click Manage, click Networking, then TCP/IP Configuration below.

From the DNS Configuration menu, select “Enter settings manually”, put whatever hostname you would like here.

VMware recommends putting a host in maintenance mode and disconnecting it from vCenter before doing this. I did this hot with my host active in an HA cluster with zero ill affects. I did it a few times just to make sure. The other way to do this is via the CLI. Connect to your ESXi host via SSH, vMA or vCLI and run:
esxcli system hostname set –host=hostname
Cool changes in Recent Tasks pane:
Not only is the Recent Tasks pane off to the right now, which I really like, it breaks out tasks by All, Running and Failed individually for easier viewing, including the ability to view your own tasks for environments with many admins. Previously these tasks were all lumped together and longer running tasks would get buried in the task stream.

The Recent Tasks pane also provides a new and better method to deal with pop-up configuration dialogs. Ever start configuring something using the old vSphere Client, get 4-5 clicks deep in the pop-up configuration, then realize you need some other piece of information requiring you to cancel out so you can go back to some other area in vCenter? This problem is now resolved in the web client with a cool new section of the Tasks pane called Work in Progress. It doesn’t matter what you’re doing or how far along you are in the dialog. If you need to break away for any reason, you can simply minimize the pop up and come back to it later. These minimized pop-ups will show in the Work in Progress pane below recent tasks.

The example here shows 3 concurrent activities in various states: a vMotion operation, a VM edit settings and a clone operation of the same VM even. Any activity that generates a pop-up dialog can be set aside and picked up again later. This is a huge improvement over the legacy vSphere Client. Very cool!!
Traffic Shaping:
It appears that in the web client you can only apply traffic shaping at the vSwitch level, not at an individual port group or VMK level. Here you can see shaping available for the standard vSwitch:

These settings, while viewable in the VMK policies summary, are not changeable (that I can see).

To override the vSwitch shaping policy and apply one to an individual port group or VMK, you have to use the legacy vSphere Client. Not sure if this is an oversight on VMware’s part or yet another sign of things to come requiring dvSwitching to assign shaping policies below the vSwitch level.

Deploying vCenter Operations Manager (vCOps):
Made extremely easy in vSphere 5.5 via the web client is the deployment of the incredible vCOps vApp for advanced monitoring of your environment. VMware has made detailed performance monitoring of your vSphere world incredibly simply and intuitive through this easy to set up and use vApp. Really impressive. From the home page, click vCenter Operations Management.

On the Getting Started screen, click Deploy vCOps. If you have a valid vmware.com login, entire it here to download the OVF and related files for deployment. You can alternatively point to the file locally if you have it already.

Accept the EULAs and choose all the placement and sizing options for the VM.
A word of caution, do not expect DRS to make a host placement decision for you here during the deployment. The wizard will allow you to select your cluster as a resource destination but the deployment will ultimately fail. Choose a specific host to deploy the VM to instead.

The requisite files will be downloaded from VMware directly and deployed to your environment. Off to the races!

Once deployed, you’ll see 2 new VMs running under the vCOps vApp object in your datacenter.

Once the VMs are powered on and the vApp has been started, you should see new options under vCenter Operations Manager.

First, click the Configure link to open the admin site in a web page. The default login for the admin account is admin/ admin, for root the password is vmware. Configure the initial setup to point to vCenter and the analytics VM which it should detect. Install the certificates as prompted and continue through the registration process.

Once complete, return to the vCOps page in vCenter and click Open, a new web page will launch for you to consume the vCOps goodness. After a short while performance stats should start pouring in for everything in your vSphere environment. Usage patterns and workload profiles can be identified so appropriate adjustments can be made. What you do from here with the data collected is entirely up to you. 🙂

A couple more screens just to show you the capability of vCOps, since I like it so much. Storage at the datastore view:

VM performance view:


































![image[64]](https://lh3.googleusercontent.com/-wYy48R7HQVQ/V_Rua5GBHsI/AAAAAAAANFo/nl_V3jv8-zc/s1600-h/image%25255B64%25255D%25255B2%25255D.png "image[64]")